Hidden Singer
배경지식
Diffusion Model (DDPM)
Latent Diffusion Model (LDM)
논문
논문의 핵심
- Hidden Singer : 오디오를 압축된 representation으로 표현하는 오토인코더 + latent 공간에서의 Diffusion Model (Latent Diffusion Model (LDM))
- 오디오를 작은 차원의 latent로 압축하는 Audio Auto Encoder
- Latent의 높은 분산을 낮게 Regularize 해주는 Residual Vector Quantization 도입
- 높은 생성 능력을 갖춘 Latent Diffusion Model (LDM) 도입
- HiddenSinger-U : Label되어있지 않은 음악 데이터에서 SVS를 학습할 수 있는 unsupervised 방법
Hidden Singer의 구조
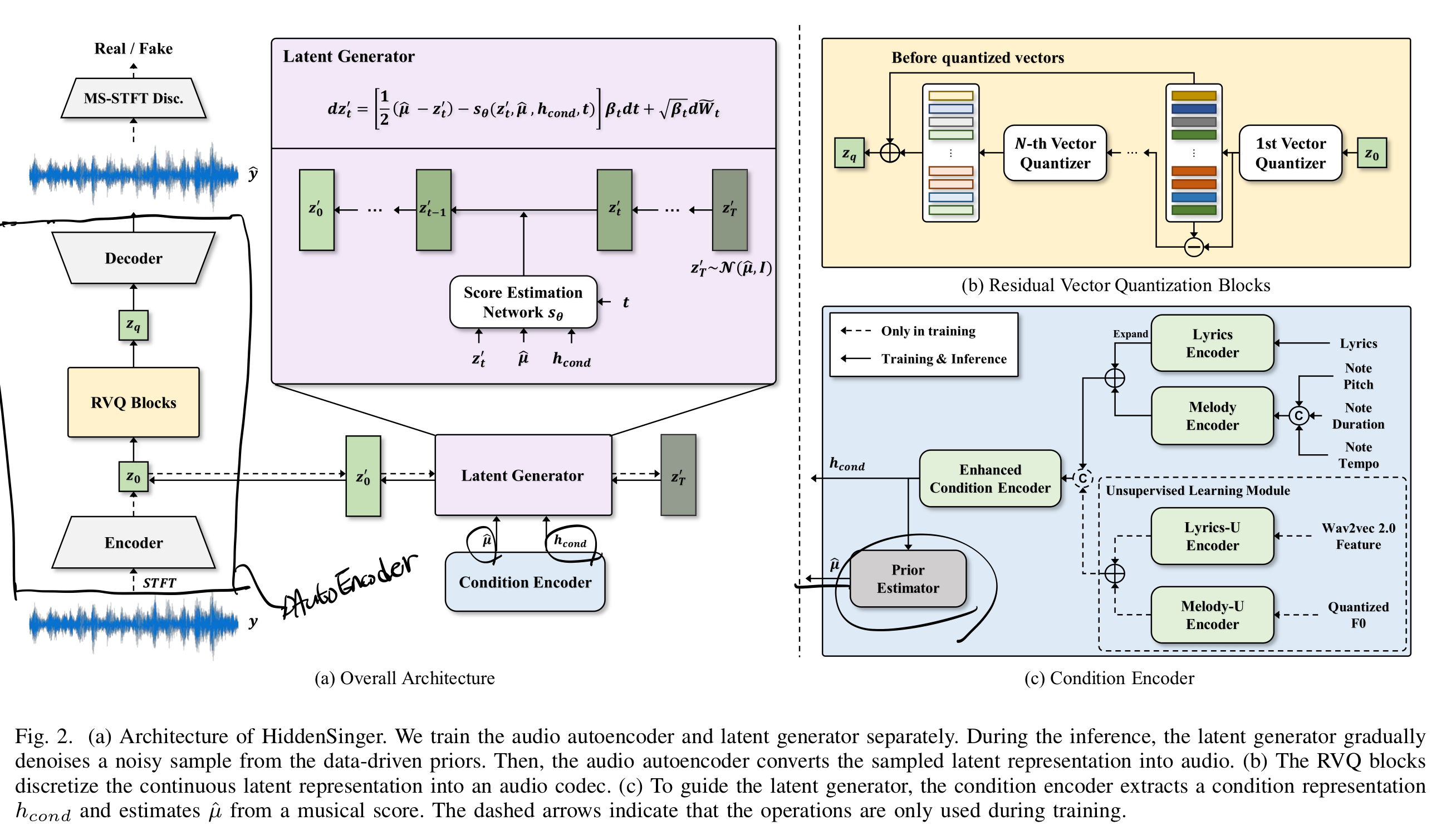
1. Audio Auto Encoder
3가지 구성 요소로 만들어진다.
- 인코더
- RVQ (Residual Vector Quantization)
- 디코더
1. Encoder
raw waveform (spectrogram과 같은)을 입력으로 받아서 어떠한 latent representation을 생성하는 모델이다. (HuBERT 참고)
기존 문헌에서는 VQ regularization을 성능 향상을 위해서 많이 사용하지만, 여기서는 대신 아래서 설명할 RVQ를 사용했다.
왜냐하면, VQ regularization은 quantized된 벡터가 원본 파형의 여러가지 feature를 동시에 표현하기에는 적합하지 않았기 때문이다.
2. RVQ 블록
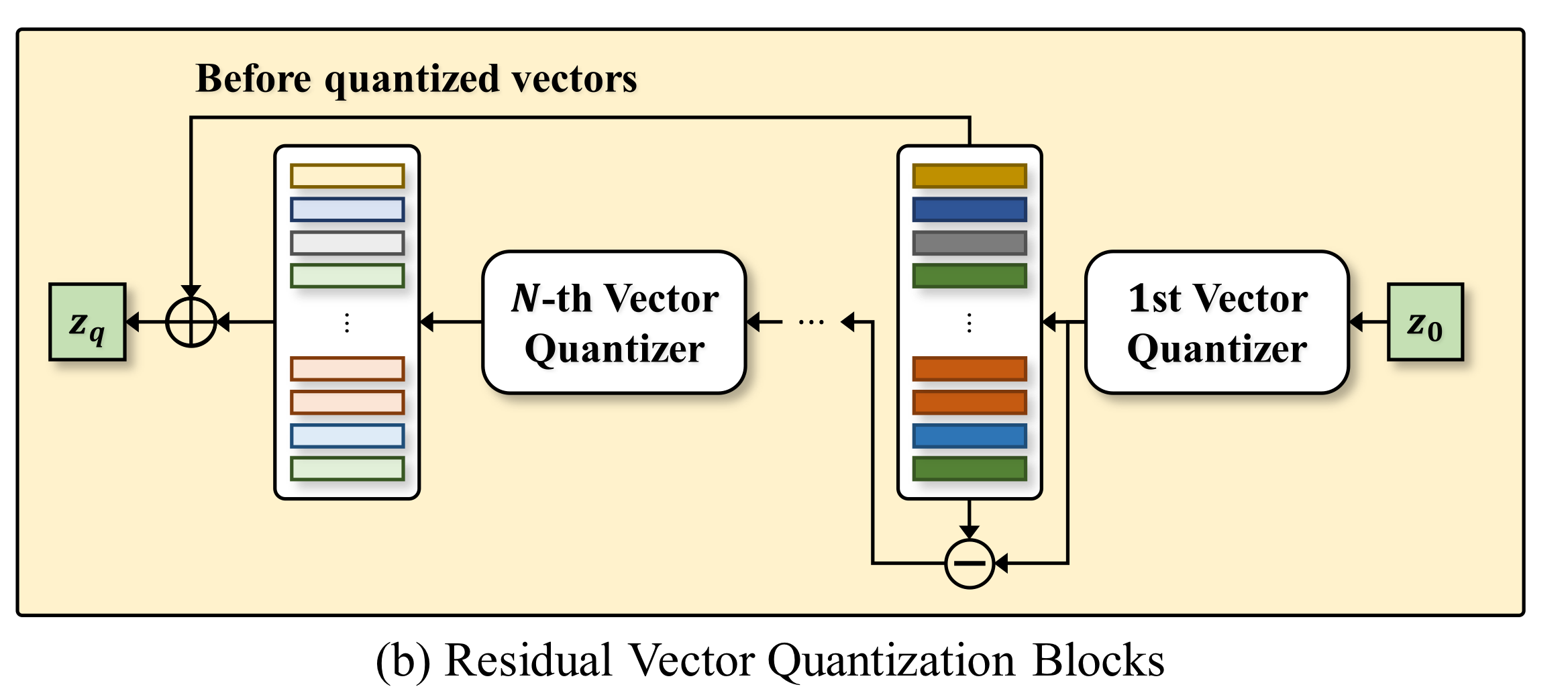
여기서 잠깐! Codebook이 뭐였는지 짚고 넘어가자. Vector Quantization 참고.
VQ를 하면 어떠한 Cluster로 각 벡터들이 바뀌게 되는데, 각각의 Cluster들을 "Codeword", 해당 codeword들이 모인 집합을 **"Codebook"**이라고 부른다.
먼저, 들어온 latent vector에 대하여 첫 번째 Vector Quantizer가 Vector Quantization을 수행.
그 이후, 두 번째 Vector Quantizer 역시 동일한 latent vector에 대하여 [[Vector Quantization]]을 수행.
이것을
이 때, 각각의 Quantizer를 훈련하는 방식은 SoundStream 논문에서 나온 방식을 따른다고 한다.
더불어, 아래의 loss를 적용하여 각각의 Quantizer (Codebook)을 훈련하도록 했다.
여기서
그러면 간단하게, 가장 가까운 cluster와의 차이를 줄이기 위한 loss라고 이해할 수 있다.
3. Decoder
디코더는 latent로부터 원래의 raw waveform을 복원한다.
또한, 원본을 잘 복원했는지 확인하는 reconstruction loss를 사용한다.
여기서
추가적인 학습을 위해서, 디코더에 GAN과 유사한 adversarial learning을 수행한다.
첫번째 loss는 Discriminator를 위한 adversarial loss이다.
해당 loss는 Discriminator가 진짜 결과물(
두 번째 loss는 Generator를 위한 adversarial loss이다.
Discriminator가 가짜 결과물(
세 번째 loss는 feature matching loss이다. 이는 perceptual loss, 즉 인간이 실제로 어떻게 시각적 (의미적)으로 보는 것인지 고려하도록 설계된 loss다. GAN의 안정적인 학습을 위해 사용한다고 한다.
Discriminator의 feature map에서 학습을 진행하는데, 실제 데이터 (gt)를 넣었을 때의 feature map과 가짜 데이터를 넣었을 때 feature map이 비슷하도록 학습이 진행된다.
그래서 Generator와 Discriminator가 비슷한 feature를 보면서 학습이 되도록 진행된다.
추가적인 정보로, multi-scale STFT 기반의 Discriminator를 사용한다고 한다.
4. Multi-task Learning
추가로 latent로부터 알맞은 가사와 악보로 singing voice를 생성하기 위하여 Connectionist Temporal Classification loss를 사용합니다.
그리하여 Autoencoder의 최종 Loss는 아래와 같습니다.
2. Condition 인코더
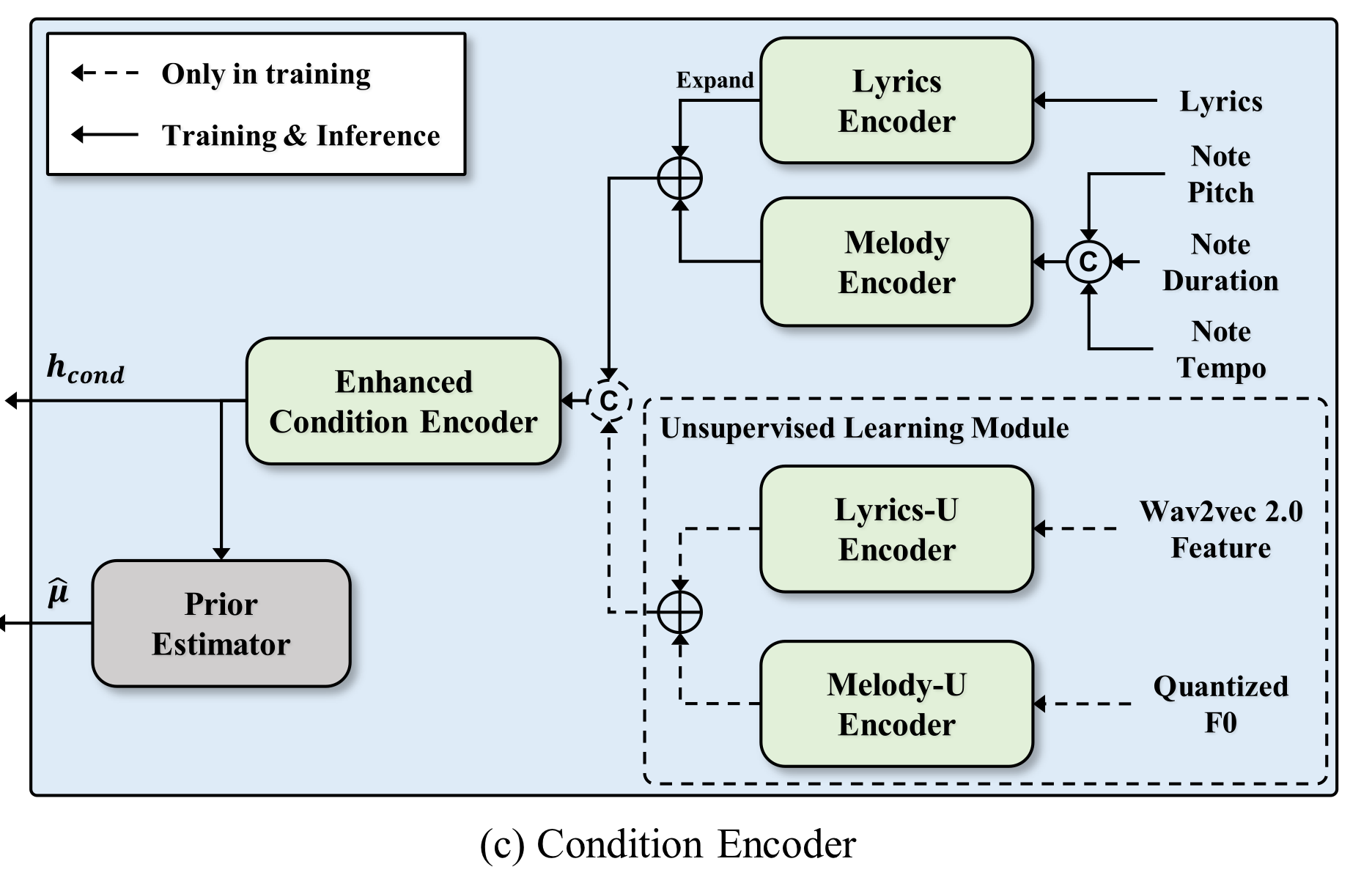
Condition 인코더는 Hidden Singer 내 생성을 위한 Latent Diffusion Model (LDM)의 Conditional Encoder이다.
Latent Diffusion Model (LDM) 논문에서 나왔듯이, Denoise 모델에서 Key와 Value에 이러한 Conditional Encoder를 넣어서 특정 조건에 알맞게 생성하도록 한다.
텍스트라면 BERT 인코더 등등을 넣겠는데, SVS에서는 가사와 악보를 조건으로 주어야 하므로, 이러한 가사 및 악보를 어떻게 인코딩해서 디퓨젼 모델에 조건을 줄 수 있는지를 설명한다.
1. 가사 인코더
가사를 인코딩하기 전, 철자 자체를 발음으로 바꾸는 외부 도구를 이용해 발음으로 바꾸어 준다.
예를 들어, "혜진이가 엄청 혼났던 그날" => "혜지니가 엄청 혼낟떤 그날" 과 같이 발음으로 바꾸어 준 후에 특정한 가사 representation으로 변환한다.
2. 멜로디 인코더
인코딩 전에, 각 악보를 발음에 알맞게 조정한다.
한국어 가사를 사용할때, 초성과 종성은 최대 3프레임으로만 조정하고, 중성은 그 나머지에 해당하도록 조정한다고 한다.
그 이후에, 악보의 음과 길이, 템포를 각각 임베딩하여 합친다.
3. Enhanced 인코더
앞의 가사와 멜로디 인코더에서 나온 벡터를 합친 이후에, Enhanced 인코더를 사용해 추가적인 정보를 주입해준다.
3. Latent Generator
앞서서 Condition에 따라 새 latent representation을 만들기 위해 Latent Diffusion Model (LDM)을 사용한다.
논문에서는 열심히 설명하는데, Diffusion Model (DDPM)에서 구한 Loss와 Latent Diffusion Model (LDM)의 conditioned generation과 크게 다르지 않아 보인다.
(아닐 수도 있음... 주의)
4. Unsupervised 학습
데이터 라벨링에 큰 자원이 소모되는 '가사 + 악보 + 음성' triplet data의 특성 상, unsupervised learning이 가능하면 굉장히 효율적인 학습이 가능하다. 이를 해결하기 위한 unsupervised 방법을 제안하는 것이다.
가수 목소리 바꾸는 것은 어떻게 못하나?
논문에서는 기존 방법의 문제점으로 가수의 목소리마다 따로 훈련을 진행해야 한다는 점을 꼽고 있다. 하지만, zero-shot adaptation과 같은 특별한 방법 외에는 크게 방도가 없다...라고 하고 이에 대한 해결책을 제시해주지는 않았다.
가사 인코더를 위해서는 self-supervised 방법을 사용한 representation을 생성했다. 그 전 연구에서 이러한 self-supervised 방법의 중간 레이어에 발음과 관련한 정보들이 담겼다고 한다. 그래서 이 representation을 그대로 사용했고, 훈련 중에 information perturbation을 사용해 발음 정보 제외에 다른 정보는 무시하도록 했다. 이 때, information perturbation은 의도적으로 노이즈를 가하거나 변형을 가하는 학습 방식이다. (목소리나 음색을 의도적으로 변형하는 등...)
멜로디 인코더를 학습하기 위해서, 먼저 오디오에서 F0 (Fundamental frequency)를 추출했고, 추출한 F0를 pitch embedding으로 바꾸어주었다. 이 pitch embedding에서 멜로디 representation을 추출했다고 한다.
unsupervised 학습을 도와주기 위해서 contrastive loss를 도입했다.
똑같은 가사 혹은 멜로디에 대한 representation은 최대한 비슷하게 하고, 다른 것에 대한 것은 최대한 다르게 만드려는 loss이며, 아래와 같다.
Latex 쓰는데에 65만년 걸림 ㅋㅋㅋㅋ
예를 들어, 가사 인코더를 훈련하는 과정이라면 실제 가사 데이터가 없는 상황에서 만든 발음 정보 represnetation
예를 들어, 가사 인코더를 훈련하는 과정이라면 실제 가사 데이터로부터 만든 발음 정보 representation
~~약간 softmax 같지 않은가? ~~
GPT에 따른 InfoNCE와 매우 유사한 모습이라고 한다. InfoNCE는 contrastive loss의 일종이다.
해석해보자면, 서로 다른 샘플의 representation은 작은 cosine similarity를 가지도록 학습되고, 서로 같은 샘플의 representation은 높은 cosine similarity를 가지도록 학습된다.
모든 loss는 최소화되는 방향으로 학습되어야 하지 않나?
그렇다. 그래서 아마 실제로 쓸 때에는
이러한 contrastive loss를 가사 인코더와 멜로디 인코더에 각각 적용하여 기존 latent generator loss에 추가적으로 적용한다.
실제 구현 방법
이 부분은 본 논문에 훨씬 자세하게 설명되어 있는데, 전체 아키텍처에 어떤 방법들이 쓰였는지 간단하게 excalidraw로 정리해 보았다.
평가 방법
1. Spectogram MAE
gt와 생성된 spectogram이 얼마나 일치하는가 MAE로 계산한다
2. Pitch Error
torchcrepe를 사용해 추출한 pitch representation 간의 차이를 본다.
3. Periodicity Error
torchcrepe를 사용해 추출한 시간별 phase feature 간의 차이를 계산한다.
4. voiced/unvoiced classification
생성한 음성이 사람의 음성으로 잘 분류되는지 classification error를 본다. => 즉 사람 음성과 비슷하도록 생성했는가?